


使用golang实现计数器、滑动窗口、漏桶、令牌桶等限流技术。
限流
限流:对请求或并发数进行限制,通过对一个时间窗口内的请求量进行限制来保障系统的正常运行,如果我们的服务资源有限,处理能力有限,就需要对调用我们的服务的上游请求进行限制,以防止自身服务由于资源耗尽而停止服务
在限流中的两个概念:
阈值:在一个单位时间内允许的请求量,如QPS限制为10,说明1秒内最多接收10次请求。
拒绝策略:超过阈值的请求的拒绝策略,常见的拒绝策略有直接拒绝、排队等待。
计数器(固定窗口)
实现
计数器是一种最简单的限流算法,其原理就是:在一段时间间隔内,对请求进行计数,与阈值进行比较判断是否需要限流,一旦到了时间临界点,将计数器清零。
可以在程序中设置一个变量
count,当过来一个请求我就将这个数+1,同时记录请求时间。当下一个请求来的时候判断
count的计数值是否超过设定的频次,以及当前请求的时间和第一次请求时间是否在1分钟内。如果在
1分钟内并且超过设定的频次则证明请求过多,后面的请求就拒绝掉。如果该请求与第一个请求的间隔时间大于计数周期,且
count值还在限流范围内,就重置count。
常见使用redis。比如对每秒限流,可以每秒设置一个key(limit-2021-11-20-11:11:11、limit-2021-11-20-11:11:12)。首先获取当前时间拼接一个如上的key。如果key存在且未超过某个阈值就自增,超过阈值就拒绝;如果key不存在就代表这新的一秒没有请求则重置计数。
package main
import (
"log"
"sync"
"time"
)
type Counter struct {
rate int //计数周期内最多允许的请求数
begin time.Time // 计数开始时间
cycle time.Duration // 计数周期
count int // 计数周期内累计收集到的请求数
lock sync.Mutex
}
// 判断请求是否能通过
func (l *Counter) Allow() bool {
l.lock.Lock()
defer l.lock.Unlock()
if l.count == l.rate-1 {
now := time.Now()
if now.Sub(l.begin) >= l.cycle {
// 到达下一个周期,重置计数器
l.Reset(now)
return true
} else {
return false
}
} else {
l.count++
return true
}
}
func (l *Counter) Set(r int, cycle time.Duration) {
l.rate = r
l.begin = time.Now()
l.cycle = cycle
l.count = 0
}
func (l *Counter) Reset(t time.Time) {
l.begin = t
l.count = 0
}
func main() {
var lr Counter
lr.Set(3, time.Second)
var wg sync.WaitGroup
wg.Add(10)
for i := 0; i < 10; i++ {
go func(i int) {
if lr.Allow() {
log.Println("ok:", i)
} else {
log.Println("fail:", i)
}
wg.Done()
}(i)
time.Sleep(200 * time.Millisecond)
}
wg.Wait()
}
优点及适用场景
计数器方法的优点
实现简单
计数器方法的逻辑非常直观,仅需记录一个计数值和时间窗口,无需复杂的数据结构或算法。
易于开发和维护,适合资源受限的环境。
性能高
由于只需维护一个计数变量,时间复杂度为 O(1)O(1)O(1),占用的内存非常少。
在单机环境中,操作计数器的开销极小,特别是在无锁或使用原子操作的情况下。
适合短时间限流
固定时间窗口的计数器可以快速统计短时间内的请求数量。
对于简单的限流需求(如限制每秒、每分钟的请求数)非常高效。
易于扩展
结合分布式存储(如 Redis),计数器可以轻松应用于分布式系统中。
借助 Redis 的原子操作(如
INCR和EXPIRE),可以高效实现计数器的分布式限流。
适配简单业务
对于不要求高精度的限流场景,计数器已经足够,比如:
防止某个接口被过载调用。
限制某个 IP 的访问频率。
易于结合其他算法
计数器可以与其他限流算法(如滑动窗口、令牌桶)结合,增强灵活性。
例如,计数器方法可以作为滑动窗口的基础统计单元。
计数器方法的适用场景
短时间的限流需求
适合限制每秒、每分钟、每小时的请求数。
常见于限制 API 请求速率、消息发送频率等。
示例:
每秒只允许某个用户最多发送 10 条消息。
每分钟某个 IP 地址的最大访问次数限制。
单机环境下的限流
在无分布式需求的场景中,计数器方法能快速实现限流。
例如,小型系统或开发测试环境中的限流需求。
示例:
某个后台管理系统限制操作频率,防止误操作过于频繁。
简单的突发流量保护
适合对流量整体进行粗略控制,无需精确平滑流量分布。
例如,阻止某个接口短时间内的过载请求,避免系统被打垮。
示例:
电商促销期间限制某个接口的访问频率。
静态资源的限速
对某些静态资源(如图片、文件下载)的请求速率限制。
示例:
限制用户每分钟下载文件的次数。
登录、注册等简单功能的频率限制
适用于用户行为频率限制,比如防止暴力破解或垃圾注册。
示例:
用户每分钟只能尝试登录 5 次。
每个 IP 每小时只能注册 3 个新账号。
配合后台任务执行
通过计数器限制某些后台任务的执行频率,防止任务过载。
示例:
定时爬虫每分钟只能发送 100 个请求。
作为基础统计工具
用于其他复杂限流算法的基础统计,例如滑动窗口需要计数器来记录时间窗口内的请求数。
示例:
滑动窗口算法中的每个子时间段可以使用计数器来统计请求。
缺点
1. 突发流量问题
计数器方法对流量的分布假设过于简单,可能无法有效处理突发流量。
问题表现:
例如,假设一个固定时间窗口是 1 秒,允许的请求数为 100。
如果用户在 0.9 秒内发送了 100 个请求,然后在下一个时间窗口的前 0.1 秒又发送了 100 个请求,系统仍然会认为这是合法的,因为它在每个窗口内都满足限流规则。
解决方法:
使用滑动窗口算法替代固定时间窗口的计数器方法,可以更均匀地分布流量。
或者引入令牌桶算法,限制请求的速率,而不是仅依赖固定的计数。
2. 时间窗口边界问题
计数器方法将时间窗口划分为固定区间,容易在边界条件下产生误差。
问题表现:
当请求发生在时间窗口的边界(如 59 秒和 60 秒之间),计数器会将这些请求分到两个窗口,可能导致限流规则失效。
例如,59 秒发送 100 个请求,60 秒再发送 100 个请求,总数虽然超出了 100 的限制,但由于计数器只统计当前窗口的请求,系统仍然允许这些请求通过。
解决方法:
改用滑动窗口或滑动日志算法,避免严格的窗口边界问题。
在计数器基础上引入动态调整机制,结合时间戳更精确地统计请求分布。
3. 无细粒度控制
计数器方法只能统计某个时间窗口内的总请求数,无法针对更精细的流量控制场景进行管理。
问题表现:
无法区分流量的分布情况。例如,某一时间窗口内的请求可能集中在一个时间点爆发,但计数器仅统计总数,不会判断是否需要分散请求。
对不同类型的流量(如用户行为和后台任务)缺乏独立控制能力。
解决方法:
使用多级限流策略,对不同场景(如不同用户组、IP、接口)设置独立的限流规则。
引入速率控制算法(如漏桶或令牌桶),结合计数器实现更精细化的流量控制。
4. 高并发下的数据竞争
计数器在高并发场景中,需要对计数操作进行线程安全的管理。
问题表现:
直接增加或读取计数器值时,可能发生数据竞争,导致计数错误。
如果没有使用锁或原子操作,高并发下可能出现计数器被多线程同时更新的情况。
解决方法:
使用
sync.Mutex或sync/atomic等机制确保线程安全。或者采用分布式计数器(如 Redis),通过单点计数减少多线程竞争。
5. 无动态调整能力
计数器方法的参数(如时间窗口大小和最大请求数)通常在初始化时固定,无法适应流量的实时变化。
问题表现:
在高峰流量时,固定的限流规则可能导致大量请求被拒绝,影响用户体验。
在低流量时,固定的限流规则可能导致资源利用不足。
解决方法:
引入动态调整机制,根据实时流量动态调整计数器的限流参数。
结合监控系统,自动适配不同的流量模式。
6. 分布式场景下一致性问题
在分布式系统中,计数器需要在多个节点间共享,容易出现数据一致性问题。
问题表现:
多个节点同时维护计数器时,可能出现同步延迟或计数不一致的情况。
例如,一个节点认为请求数未超限,但另一个节点可能已经超限。
解决方法:
使用集中式的分布式计数器(如基于 Redis 的计数器)。
或者通过一致性协议(如 Paxos 或 Raft)确保计数器在多个节点间的一致性。
7. 无请求优先级支持
计数器方法无法区分不同优先级的请求。
问题表现:
当系统负载接近限流阈值时,高优先级请求(如支付、登录)可能被普通请求挤掉,影响关键功能的可用性。
解决方法:
引入请求优先级机制,根据优先级动态调整限流规则。
或者对关键请求设置单独的限流规则,避免被其他流量影响。
滑动窗口
实现
针对固定窗口的问题进行优化,就产生了滑动窗口的方案。滑动窗口最核心的思想在于,任何时间段的 1 分钟,最多都是 100 个请求。滑动窗口把 100 个请求分摊到了每一个格子,成个格子就是 10 秒钟,就是 6 个格子。counter 值就是可滑动的 6 个格子的总和。
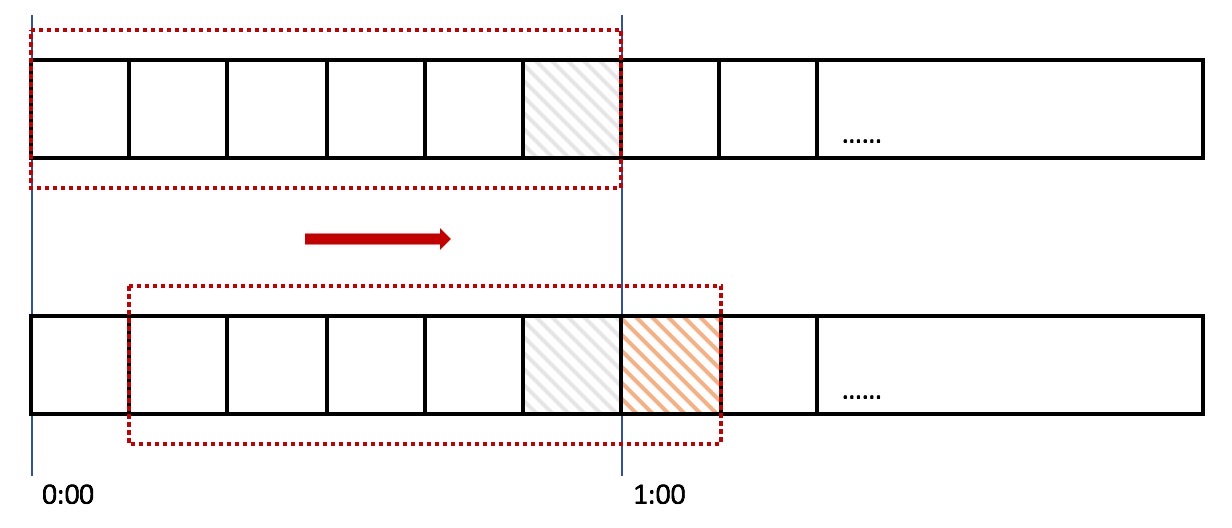
当遇到恶意用户再次在 00:59 请求时,服务可以成功处理 100 个请求,可是到 1:00 时触发 100 个请求时,由于窗口的滑动,counter 总数已经到了第 2- 第7 个格子的和,counter 得到 200 个请求从而触发了限流。可见滑动窗口的时间段永远是最新的 “1 分钟”。只要格子分的粒度足够细,限流实现的精度就越高。
主要就是实现sliding window算法。可以参考Bilibili开源的kratos框架里circuit breaker用循环列表保存time slot对象的实现,他们这个实现的好处是不用频繁的创建和销毁time slot对象
package main
import (
"fmt"
"sync"
"time"
)
var winMu map[string]*sync.RWMutex
func init() {
winMu = make(map[string]*sync.RWMutex)
}
// 时间窗口
type timeSlot struct {
timestamp time.Time // 时间起点
count int // 落在这个timeSlot内的请求数
}
func countReq(win []*timeSlot) int {
var count int
for _, ts := range win {
count += ts.count
}
return count
}
// 滑动窗口
type SlidingWindowLimiter struct {
SlotDuration time.Duration // time slot 的长度
WinDuration time.Duration // sliding window的长度
numSlots int // window内最多有多少个slot
maxReq int // win duration 内允许的最大请求数
windows map[string][]*timeSlot
}
// 生成滑动窗口
func NewSliding(slotDuration time.Duration, winDuration time.Duration, maxReq int) *SlidingWindowLimiter {
return &SlidingWindowLimiter{
SlotDuration: slotDuration,
WinDuration: winDuration,
numSlots: int(winDuration / slotDuration),
windows: make(map[string][]*timeSlot),
maxReq: maxReq,
}
}
// 获取user_id/ip的时间窗口
func (l *SlidingWindowLimiter) getWindow(uidOrIp string) []*timeSlot {
win, ok := l.windows[uidOrIp]
if !ok {
win = make([]*timeSlot, 0, l.numSlots)
}
return win
}
func (l *SlidingWindowLimiter) storeWindow(uidOrIp string, win []*timeSlot) {
l.windows[uidOrIp] = win
}
func (l *SlidingWindowLimiter) validate(uidOrIp string) bool {
// 同一user_id/ip并发安全
mu, ok := winMu[uidOrIp]
if !ok {
var m sync.RWMutex
mu = &m
winMu[uidOrIp] = mu
}
mu.Lock()
defer mu.Unlock()
win := l.getWindow(uidOrIp)
now := time.Now()
// 将已经过期的time slot移除时间窗
timeoutOffest := -1
for i, ts := range win {
if ts.timestamp.Add(l.WinDuration).After(now) {
break
}
timeoutOffest = i
}
if timeoutOffest > -1 {
win = win[timeoutOffest+1:]
}
// 判断请求是否超限
var result bool
if countReq(win) < l.maxReq {
result = true
}
// 记录本次的请求数
var lastSlot *timeSlot
if len(win) > 0 {
lastSlot = win[len(win)-1]
// 判断当前请求是否存在与最后一个时间槽中,不存在则新创建一个时间窗口,否则在最后一个时间窗口加1
if lastSlot.timestamp.Add(l.SlotDuration).Before(now) {
lastSlot = &timeSlot{timestamp: now, count: 1}
win = append(win, lastSlot)
} else {
lastSlot.count++
}
} else {
lastSlot = &timeSlot{timestamp: now, count: 1}
win = append(win, lastSlot)
}
l.storeWindow(uidOrIp, win)
return result
}
func (l *SlidingWindowLimiter) getUidOrIp() string {
return "127.0.0.1"
}
func (l *SlidingWindowLimiter) IsLimited() bool {
return !l.validate(l.getUidOrIp())
}
func main() {
limiter := NewSliding(100*time.Millisecond, time.Second, 10)
for i := 0; i < 5; i++ {
fmt.Println(limiter.IsLimited())
}
time.Sleep(100 * time.Millisecond)
for i := 0; i < 5; i++ {
fmt.Println(limiter.IsLimited())
}
fmt.Println(limiter.IsLimited())
for _, v := range limiter.windows[limiter.getUidOrIp()] {
fmt.Println(v.timestamp, v.count)
}
fmt.Println("a thousand years later...")
time.Sleep(time.Second)
for i := 0; i < 7; i++ {
fmt.Println(limiter.IsLimited())
}
for _, v := range limiter.windows[limiter.getUidOrIp()] {
fmt.Println(v.timestamp, v.count)
}
}
优点及适用场景
滑动窗口的优点
更加精确的限流
滑动窗口相比于固定窗口计数器,可以更精确地统计请求的分布情况,不会因为时间窗口的边界效应导致限流的误差。
更平滑地处理流量,适合对流量精准控制的场景。
适应突发流量
能够部分容忍短时间的流量突增,只要整体请求数量在规定范围内,就不会直接拒绝请求。
降低因为瞬时流量过高而导致误判的可能性。
实时性高
滑动窗口随着时间的推进,会动态调整统计的时间段,更能反映当前的流量情况。
尤其适合需要快速响应的实时场景。
限流逻辑灵活
可以自由选择窗口长度和滑动粒度,以适应不同的业务需求:
窗口长度决定了流量统计周期。
滑动粒度可以控制限流的精度。
减少不必要的请求拒绝
通过移动时间窗口,滑动窗口避免了固定窗口方法在时间边界上对请求的过于严格的限制。
更好地平衡了用户体验和系统保护。
便于实现分布式限流
滑动窗口配合分布式存储(如 Redis)可以较容易地实现分布式限流,适用于分布式系统。
滑动窗口的适用场景
API 网关限流
需要精确控制接口的访问频率,以避免过载。
比如,某 API 网关对单个 IP 或单个用户的访问速率限制。
示例:
每 5 分钟内最多允许某用户发起 500 次请求。
防止爬虫抓取
控制爬虫访问频率,避免系统被过度抓取。
滑动窗口允许一定的突发流量,不会因为短时间的抓取而直接封禁。
示例:
每分钟最多允许某 IP 抓取 1000 条数据。
动态调整的限流需求
适用于需要实时监控并调整的限流场景。
滑动窗口能及时反映流量的变化。
示例:
实时流量监控系统,控制每小时的接口调用总量。
防止暴力破解
限制用户登录请求频率,防止暴力破解。
滑动窗口能更精准地判断用户的异常行为。
示例:
用户每 10 分钟最多允许尝试登录 10 次。
电商系统的限购限制
在电商场景中,用于控制用户的购买频率或订单提交频率。
滑动窗口可以允许一定范围内的突发购买行为。
示例:
每个用户在 30 分钟内最多提交 5 个订单。
数据处理任务的流量控制
在数据处理场景中,对流量进行细粒度的限制,防止任务过载。
滑动窗口的实时性可防止因为瞬时突发流量导致的系统崩溃。
示例:
实时流媒体系统中,每秒最多处理 200 条消息。
分布式系统中的限流
配合分布式存储(如 Redis)实现限流,滑动窗口能高效地在多节点间协调。
分布式环境中,滑动窗口能避免过多的资源浪费。
示例:
分布式文件存储系统中,每 10 分钟内单个用户最多上传 500 MB 文件。
缺点
1. 时间粒度问题
滑动窗口的时间粒度由 SlotDuration 决定,时间槽越大,统计的精确度越低。
问题表现:
如果
SlotDuration设置为 1 秒,那么所有在同一秒内的请求都会被统计到同一个时间槽中。即使在时间槽边界(如 12:00:00 和 12:00:01)发送了大量请求,它们仍可能被统计为符合限流规则,从而导致“瞬时流量激增”问题。
解决方法:
缩小
SlotDuration,提高时间粒度,例如设置为毫秒级。或者使用 滑动窗口日志(Sliding Log)算法,精确记录每次请求的时间。
2. 过期时间槽的内存管理
滑动窗口需要定期移除过期的时间槽,否则会导致内存使用的增长。
问题表现:
在流量高峰时,窗口中可能会存在大量的时间槽。
如果没有及时清理过期时间槽,内存占用可能会增加,影响性能。
解决方法:
定期移除过期的时间槽(代码中已有此逻辑,通过遍历
win来移除过期槽)。可以引入定期清理任务,避免在高并发下频繁遍历。
3. 处理边界情况的复杂性
在滑动窗口中,需要处理时间槽边界的各种复杂情况:
问题表现:
比如请求刚好跨越两个时间槽,如何统计会变得复杂。
可能导致计算不准确,例如时间槽的边界条件未考虑到,导致漏计或超计请求。
解决方法:
在设计和实现时,需要充分考虑边界条件,确保逻辑正确性。
4. 高并发下的锁竞争
滑动窗口算法中需要对用户的时间窗口进行更新,这通常会使用锁(如 sync.Mutex 或 sync.RWMutex)来保证并发安全。
问题表现:
如果某个用户的请求非常频繁(如每毫秒一次),锁可能会成为性能瓶颈,导致吞吐量下降。
高并发情况下,大量线程同时访问同一时间窗口,可能导致锁争用严重。
解决方法:
使用更细粒度的锁,例如为每个用户单独维护锁(代码中已有类似实现)。
或者引入无锁数据结构,如基于原子操作的算法。
5. 请求分布的假设问题
滑动窗口假设请求分布是均匀的,但实际场景中可能并非如此。
问题表现:
某些时间段(如秒或毫秒级)内可能突然出现高并发请求,导致限流逻辑失效。
例如,在
SlotDuration较大的情况下,某个时间槽内的请求数可能瞬间超出预期。
解决方法:
如果需要处理不均匀的请求分布,可以结合其他限流算法,如 令牌桶算法 或 漏桶算法,以实现更平滑的流量控制。
6. 全局状态的维护成本
滑动窗口需要维护每个用户(或 IP 地址)对应的窗口状态。
问题表现:
在高并发环境下,需要存储大量的用户或 IP 时间窗口,增加了内存和计算成本。
如果流量中有大量短期访问的用户(如爬虫或无状态请求),窗口状态会迅速膨胀。
解决方法:
定期清理不活跃用户的时间窗口数据。
引入缓存淘汰策略(如 LRU 或 LFU)来控制内存占用。
7. 动态调整能力不足
滑动窗口的参数(如 SlotDuration 和 WinDuration)在初始化时固定,无法根据实时流量动态调整。
问题表现:
在流量激增时,固定的限流规则可能不足以有效保护系统。
在流量较小时,又可能导致资源浪费。
解决方法:
引入动态参数调整机制,根据实时流量动态调整
SlotDuration和WinDuration。可以结合流量预测算法或监控系统实现动态限流。
漏桶算法
实现
当有请求到来时先放到木桶中,worker以固定的速度从木桶中取出进行相应的操作,如果木桶已经满了,直接返回请求频率超限的错误码或者页面
特点:
漏桶具有固定的容量,出水速率是固定常量(流出请求)
如果桶是空的,则不需要流出水滴
可以以任意速率流入水滴到漏桶(流入请求)
如果流入水滴超出了桶的容量,则流入的水滴溢出(新请求被拒绝)
漏桶限制的是常量流出速率(即流出速率是一个固定常量值),所以最大的速率就是出水的速率,不能出现突发流量。
通常使用队列来实现,在go语言中可以通过buffered channel来快速实现,任务加入channel,开启一定数量的 worker 从 channel 中获取任务执行
package main
import (
"context"
"fmt"
"sync"
"time"
)
// 封装业务逻辑的执行结果
type Result struct {
Msg string
}
// 执行的业务逻辑函数
type Handler func() Result
// 每个请求来了,把需要执行的业务逻辑封装成Task,放入木桶,等待worker取出执行
type Task struct {
handler Handler // worker从木桶中取出请求对象后要执行的业务逻辑函数
resChan chan Result // 等待worker执行并返回结果的channel
taskID int
}
func NewTask(id int, handler Handler) Task {
return Task{
handler: handler,
resChan: make(chan Result),
taskID: id,
}
}
// 漏桶
type LeakyBucket struct {
BucketSize int // 木桶的大小
WorkerNum int // 同时从木桶中获取任务执行的worker数量
bucket chan Task // 存方任务的木桶
}
func NewLeakyBucket(bucketSize int, workNum int) *LeakyBucket {
return &LeakyBucket{
BucketSize: bucketSize,
WorkerNum: workNum,
bucket: make(chan Task, bucketSize),
}
}
func (b *LeakyBucket) AddTask(task Task) bool {
// 如果木桶已经满了,返回false
select {
case b.bucket <- task:
default:
fmt.Printf("request[id=%d] is refused\n", task.taskID)
return false
}
// 如果成功入桶,调用者会等待worker执行结果
resp := <-task.resChan
fmt.Printf("request[id=%d] is run ok, resp[%v]\n", task.taskID, resp)
return true
}
func (b *LeakyBucket) Start(ctx context.Context) {
// 开启worker从木桶拉取任务执行
for i := 0; i < b.WorkerNum; i++ {
go func(ctx context.Context) {
for {
select {
case <-ctx.Done():
return
default:
task := <-b.bucket
result := task.handler()
task.resChan <- result
}
}
}(ctx)
}
}
func main() {
bucket := NewLeakyBucket(10, 4)
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
bucket.Start(ctx) // 开启消费者
// 模拟20个并发请求
var wg sync.WaitGroup
wg.Add(20)
for i := 0; i < 20; i++ {
go func(id int) {
defer wg.Done()
task := NewTask(id, func() Result {
time.Sleep(300 * time.Millisecond)
return Result{}
})
bucket.AddTask(task)
}(i)
}
wg.Wait()
time.Sleep(10 * time.Second)
}优点及适用场景
漏桶算法的优点
平滑流量输出
漏桶算法能够将突发流量平滑地处理,以稳定的速率输出请求,防止系统被瞬时高流量冲垮。
限制了请求的平均速率,即使短时间内流量激增,也不会影响整体吞吐量。
适用于对流量稳定性要求较高的场景,如带宽控制或请求速率限制。
严格的流量控制
与滑动窗口相比,漏桶算法能严格限制流量的最大速率,避免流量突发对系统造成冲击。
任何请求必须按设定速率通过,不会因短时间内的高流量而放宽限制。
对于敏感资源(如数据库、第三方 API),可以确保不超过允许的调用频率。
防止队列堆积
漏桶算法不会无限制地积累请求,而是强制丢弃超出桶容量的请求,防止系统过载。
避免了大量请求堆积导致的系统崩溃。
适用于需要强制丢弃超量请求的场景,如 API 限流和消息队列控制。
简单易实现
漏桶算法实现逻辑简单,易于理解和维护。
只需维护一个桶容量和一个漏水速率,即可控制请求流量。
在分布式系统中,结合 Redis 计数器或定时任务即可实现限流。
漏桶算法的适用场景
网络带宽控制
适用于网络流量的平滑控制,确保数据传输不会因突发流量影响整体网络性能。
示例:
限制用户每秒只能上传 1MB 数据,即使短时间内流量增加,也会按照固定速率处理。
API 限流
防止 API 被过度调用,确保服务的可用性和稳定性。
示例:
限制某 API 每秒最多处理 100 个请求,多余的请求直接丢弃。
任务队列调度
在任务处理系统中,控制任务的处理速率,防止瞬时高负载导致系统崩溃。
示例:
限制后台任务处理系统每秒只能处理 50 个任务。
防止缓存击穿
当某些热点数据失效时,限制访问速率,防止数据库因大量请求而崩溃。
示例:
当缓存失效后,限制数据库查询的速率,确保数据库不会因短时间内大量查询而被压垮。
金融交易限流
在金融系统中,限制用户的交易请求速率,防止恶意操作或交易系统崩溃。
示例:
每个用户每分钟最多提交 10 笔交易请求,超出部分直接丢弃。
漏桶算法的缺点
无法适应突发流量
问题表现:
漏桶算法严格按照固定速率处理请求,不能灵活应对突发流量。
可能导致部分可接受的短时高峰流量被丢弃,影响用户体验。
解决方法:
结合令牌桶算法,在桶内存储一定量的突发请求额度,提高灵活性。
请求排队可能导致响应延迟
问题表现:
如果桶内的请求数量过多,处理速率较低,可能导致请求处理延迟。
用户可能需要等待较长时间才能获得响应。
解决方法:
设定最大等待时间,超时的请求直接丢弃。
动态调整漏水速率,在流量较小时加快处理速度。
全局状态维护成本高
问题表现:
需要持续跟踪桶的状态,包括桶的剩余容量和出水速率。
在高并发分布式环境下,需要额外的存储和计算资源来同步桶状态。
解决方法:
采用 Redis 计数器存储桶状态,实现分布式限流。
使用分片策略,针对不同用户或服务实例单独维护漏桶状态,减少全局锁竞争。
动态调整能力不足
问题表现:
固定的漏水速率可能无法适应不同流量模式,导致系统资源利用率低。
在低流量时,仍然按固定速率漏水,可能导致资源浪费。
解决方法:
结合 AI 预测或实时监控系统,动态调整漏水速率。
采用自适应限流策略,在流量较小时增加处理速率,提高资源利用率。
内存占用高
问题表现:
需要存储桶内未处理的请求信息,导致内存开销较大,特别是在长时间窗口的情况下。
解决方法:
只存储必要的统计数据,而不是每个请求的详细信息。
采用 Redis 过期键机制,定期清理过期请求,降低内存占用。
令牌桶算法
实现
令牌桶算法(Token Bucket)是网络流量整形(Traffic Shaping)和速率限制(Rate Limiting)中最常使用的一种算法。典型情况下,令牌桶算法用来控制发送到网络上的数据的数目,并允许突发数据的发送。想象有一个木桶,以固定的速度往木桶里加入令牌,木桶满了则不再加入令牌。服务收到请求时尝试从木桶中取出一个令牌,如果能够得到令牌则继续执行后续的业务逻辑;如果没有得到令牌,直接返回反问频率超限的错误码或页面等,不继续执行后续的业务逻辑。
特点:
由于木桶内只要有令牌,请求就可以被处理,所以令牌桶算法可以支持突发流量。同时由于往木桶添加令牌的速度是固定的,且木桶的容量有上限,所以单位时间内处理的请求数目也能够得到控制,起到限流的目的。假设加入令牌的速度为 1token/10ms,桶的容量为500,在请求比较的少的时候(小于每10毫秒1个请求)时,木桶可以先"攒"一些令牌(最多500个)。当有突发流量时,一下把木桶内的令牌取空,也就是有500个在并发执行的业务逻辑,之后要等每10ms补充一个新的令牌才能接收一个新的请求。
木桶的容量 - 考虑业务逻辑的资源消耗和机器能承载并发处理多少业务逻辑。生成令牌的速度 - 太慢的话起不到“攒”令牌应对突发流量的效果。
令牌按固定的速率被放入令牌桶中
桶中最多存放
B个令牌,当桶满时,新添加的令牌被丢弃或拒绝如果桶中的令牌不足
N个,则不会删除令牌,且请求将被限流(丢弃或阻塞等待)
令牌桶限制的是平均流入速率(允许突发请求,只要有令牌就可以处理,支持一次拿3个令牌,4个令牌…),并允许一定程度突发流量。
假设每100ms生产一个令牌,按user_id/IP记录访问最近一次访问的时间戳 t_last 和令牌数,每次请求时如果 now - last > 100ms, 增加 (now - last) / 100ms个令牌。然后,如果令牌数 > 0,令牌数 -1 继续执行后续的业务逻辑,否则返回请求频率超限的错误码或页面。
package main
import (
"fmt"
"sync"
"time"
)
type TokenBucket struct {
lock sync.Mutex
rate time.Duration // 多长时间生成一个令牌
capacity int //桶的容量
tokens int // 当前桶中token的数量
last time.Time // 桶上次放token的时间戳
}
func NewTokenBucket(bucketSize int, tokenRate time.Duration) *TokenBucket {
return &TokenBucket{
capacity: bucketSize,
rate: tokenRate,
}
}
// 验证是否能获取一个令牌,返回是否被限流
func (t *TokenBucket) Allow() bool {
t.lock.Lock()
defer t.lock.Unlock()
now := time.Now()
if t.last.IsZero() {
// 第一次访问初始化最大令牌数
t.last, t.tokens = now, t.capacity
} else {
if t.last.Add(t.rate).Before(now) {
// 如果now与上次请求间隔超过了 token rate
// 增加令牌, 更新last
t.tokens += int(now.Sub(t.last) / t.rate)
if t.tokens > t.capacity {
t.tokens = t.capacity
}
t.last = now
}
}
if t.tokens > 0 {
t.tokens--
return true
}
// 没有令牌拒绝
return false
}
func main() {
tokenBucket := NewTokenBucket(5, 100*time.Millisecond)
for i := 0; i < 10; i++ {
fmt.Println(tokenBucket.Allow())
}
time.Sleep(100 * time.Millisecond)
fmt.Println(tokenBucket.Allow())
}buffered channel 来完成简单的加令牌取令牌操作。
package main
import (
"fmt"
"time"
)
func main() {
// 向令牌桶添加令牌的时间间隔
var fillInterval = time.Millisecond * 10
var capacity = 100
// 初始化令牌桶,使用buffer channel
var tokenBucket = make(chan struct{}, capacity)
fillToken := func() {
ticker := time.NewTicker(fillInterval)
for {
select {
case <-ticker.C:
select {
case tokenBucket <- struct{}{}:
default:
}
fmt.Println("current token cnt:", len(tokenBucket), time.Now())
}
}
}
go fillToken()
time.Sleep(time.Hour)
}优点及适用场景
令牌桶的优点:
灵活性高:
令牌桶算法可以平滑流量控制,允许突发流量(短时间内的高并发请求),但也能确保长期流量不会超过设定的速率。
与固定速率的限流方法不同,令牌桶允许请求以突发模式进入,在流量突增时能有效处理。
支持平滑流量控制:
令牌桶的工作机制可以平滑请求流量。例如,如果令牌桶内存储的令牌数量不足以处理当前请求,算法会根据桶中剩余的令牌数控制流量,从而避免系统过载。
处理突发流量:
与固定窗口限流算法(如滑动窗口)相比,令牌桶能处理突发流量。如果请求频率较低但突然出现大量请求,令牌桶可以根据桶内存储的令牌量,迅速处理这些请求,避免了流量的突发性引发系统崩溃。
平衡系统负载:
令牌桶算法通过控制令牌的发放速率,避免了长时间内请求数过多,从而平衡了系统负载,防止过载导致性能下降。
适应性强:
令牌桶可以通过调整令牌产生速率和桶的大小来适应不同的场景需求,适用于高并发或突发性请求场景。
令牌桶的适用场景:
API 请求限流:
在 API 服务中,令牌桶算法常用于限流,特别是在需要处理突发流量时。可以允许用户在短时间内发送大量请求(突发流量),但在长时间内请求频率保持在一定的速率内。例如,社交网络平台、支付网关等。
网络带宽控制:
令牌桶算法常用于控制网络带宽,限制数据传输速率,尤其是在分布式系统中,用于流量控制。令牌桶可以确保网络传输不会超过指定速率,避免拥塞。
实时数据流处理:
在需要处理高频或不稳定流量的数据流场景中,令牌桶算法有助于平衡数据流的输入,确保系统的稳定性。例如,视频流媒体服务、日志数据采集系统等。
防止系统过载:
在高并发场景下,令牌桶可以有效地限制系统的负载,避免系统因过载而崩溃或降低响应速度。例如,电子商务网站的支付系统或流量高峰期的注册接口。
边缘计算与物联网:
在边缘计算或物联网场景中,令牌桶算法被用来限制传感器数据的上传频率,避免大量设备的突发请求超载边缘设备或云服务器。
视频直播和音频流控制:
在视频直播、音频流或直播推流的应用场景中,令牌桶算法可以帮助控制带宽的使用,保证每秒钟的请求数量不超标,同时允许短时间内的请求峰值。
缺点
1. 请求突发问题
问题表现:
令牌桶算法适用于平滑请求流量,但在某些高并发场景中,短时间内的请求可能会迅速消耗令牌,导致后续请求被限流,无法及时处理。
如果流量突然激增,桶内令牌可能不足以应对激增的请求,可能出现请求排队或拒绝服务的情况。
解决方法:
增加桶的容量(即令牌的最大数量),允许桶内缓存更多的令牌,从而处理更高频次的请求。
结合其他限流算法(如滑动窗口)来平衡突发请求与平稳请求的处理。
2. 令牌生成速率不匹配实际需求
问题表现:
令牌生成的速率是固定的,但在实际应用中,流量可能是动态的,不同时间段的请求量可能有很大的差异。
在流量较低的情况下,令牌生成速率可能会导致空闲时间的资源浪费,而在流量激增时,令牌生成速率可能跟不上请求的数量。
解决方法:
动态调整令牌生成速率,基于流量监控或预测算法来动态调整令牌生成的速率,以适应不同时间段的请求需求。
3. 资源浪费
问题表现:
令牌桶算法可能会出现桶内存储了大量未使用的令牌,尤其是在流量较低的情况下,这些令牌会浪费系统资源。
如果系统没有合理的机制来丢弃无效的令牌,会增加内存的消耗。
解决方法:
通过引入令牌过期机制或设置合理的最大令牌数,确保桶内的令牌在合理的时间内消耗完毕,减少系统的资源浪费。
4. 极端流量情况下的限制
问题表现:
如果请求流量在短时间内突然增加且超过了令牌桶的容量,即使有剩余令牌生成速率,可能仍然无法处理所有请求,导致请求被丢弃或延迟。
解决方法:
增加桶的容量,允许更多令牌存储,但这会导致内存占用的增加。
结合其他限流算法,如滑动窗口,令牌桶与滑动窗口算法的结合可以平衡极端流量的处理能力。
5. 不适应非平稳流量模式
问题表现:
令牌桶假设请求的流量是较为平稳的,但在某些实际应用场景中,流量波动较大,令牌桶的静态生成速率可能无法适应这种变化。
解决方法:
引入智能流量控制机制,结合实时流量分析和预测,动态调整令牌生成速率,提升对非平稳流量模式的适应能力。
参考连接:
https://www.cnblogs.com/niumoo/p/16007224.html
https://ihui.ink/post/systemarch/00-limiter-algo/
https://yindongliang.com/posts/go-rate-limit/#%E6%BB%91%E5%8A%A8%E7%AA%97%E5%8F%A3